In the last blog series, I referenced a presentation by Ryan Dahl on NodeJS and wanted to explore the concepts in that talk more. It can be easy to dismiss JavaScript as a low-performance language based on the observation that it is a single-threaded environment. However, this talk directly opposes that mindset. Instead, it suggests that the real problem is removing I/O from the hot path. Data locality is often the place where performance tradeoffs live. Generally speaking, even the slowest arithmetic operations, like division, cosine, and sine, are significantly faster than reading from RAM. Reading from disk or the network is orders of magnitude slower than reading from RAM. The key argument is that if you keep a single loop completely saturated while pushing blocking IO out of the hot path, you can get better performance at a reduced memory cost. This is because threading comes at a performance cost. For starters, each thread comes with its own memory. At a minimum, every thread has its own stack, which easily consumes 1 megabyte or more of memory. Also, once you have shared memory between threads, you have mutexes that can create bigger problems than single-threaded code.
Thinking about this a bit more, I decided it might be fun to try building out a simple event loop on a contained problem to better understand this space.
Doing some research
Before I got too into this, I wanted to get a better understanding of what was under the hood of NodeJS. Going into this, I knew that NodeJS was largely a C++ project with V8 bindings. However, I was a bit less familiar with the machinery it used to handle its non-blocking IO. After some research, I found that modern NodeJS uses libuv to handle this. This library handles everything from file access and child processes to sockets and DNS resolution. This struck me as a little bit odd. In the presentation I referenced, Ryan mentioned using libev to handle eventing. In an attempt to figure out what happened, I started digging. Looked into that library I found it was related to yet another eventing library, libevent. Each library added its own unique features to improve performance in event loops. As it turns out, Ryan Dahl even wrote about all of these libraries and why they decided to create libuv.
In many of these libraries, the key difference revolves around the OS support they provide and the APIs they build on. Many point to the difference between select, poll, and epoll. Each gives different performance benefits along the way. Since many of these optimizations operate at the boundary between userland and the kernel, it can be quite difficult to create a multi-platform, performant, and coherent API.
Setting up an experiment
While most of the literature on these eventing libraries had focused on sockets, I was a bit more preoccupied with file access. I was still fixated on the original code that brought this all up, forcing a synchronous call for file access in NodeJS. Unfortunately, this was the one case where not all kernels provided good non-blocking IO APIs. Because of this, utilizing things like epoll didn't fit naturally into this problem. However, there was still a way to move forward with building an event loop and taking blocking IO off of the hot path.
Building up the scenario
Before I could do anything, I had to set something up to test file access. I decided it would be easy to test reading JavaScript files and doing some very basic parsing. Each file would have a collection of imports, a handful of constants, and some functions. The processing code would count the total constants and functions found across all files and queue up processing the imports.
Doing some basic research, I found that a reasonable range of files for a project would be around 10 files for a smaller project and closer to 1000 for a larger project. Since I didn't want to manually create that many files, I decided the best way to bootstrap this experiment was to write a NodeJS program to generate these projects. I wanted imports, but I also didn't want any circular references. I assumed circular references could lead to complications during processing. I pulled out Tarjan's algorithm to make sure no circular references got generated. Also, to make it easier to parse, I parsed the graph at the very end and I referenced all roots in an index.js.
Also, to entertain myself, I created a list of predefined words to combine for the naming of files and variables. This led to funny file names like help-overwhelming-random.js, malware-darwin.js, and sqs-agentic-wheel-tokenizer.js.
Figuring out what to test
Armed with the ability to create JavaScript projects, I now needed to decide what to test. Part of my interest was comparing the performance of different cases across NodeJS and C. This resulted in the following applications being created.
- A NodeJS application that blocks on IO by using the sync APIs.
- A NodeJS application that used the async libraries correctly.
- A C application that blocked on IO.
- A C application that used an event loop.
Also, since projects could be of different sizes, I decided each program would be tested against a handful of different projects.
- A tiny project with 10 files.
- A small project with 50 files.
- A medium project with 100 files.
- A large project with 500 files.
- An extra-large project with 1500 files.
With all of these, I would gather timings and compare how they did.
Benchmarking file access is tricky
Before I go into the specifics of each example, I want to preface with a little benchmarking tidbit. While I was conducting this experiment, I realized that I was getting some crazy outliers in my initial testing. Those who are closer to the OS and file-based performance will know where I am going with this. OS's know that file access is slow and attempt to compensate for this. In some cases, quite aggressively. In my case, I would see a massive boost on the second run of a program. For these tests, I was running on a MacBook using an M3 chip. The best way I could find to get the lowest variance in these tests was to sudo purge between each run.
I was a bit concerned about how specialized the M series architecture was, so I conducted another round of tests on a Linux-based machine. Linux also had similar caching that needed to be cleared between each run.
I suggest taking the exact numbers with a grain of salt, and instead focus more on the trend than the result.
Running the test
Each of these programs had required a bit of different effort. Admittedly, I hadn't written much C in the past 15 years, so it took me a while to get back into the swing of things.
Blocking NodeJS example
This was the easiest one to write. I didn't want to do a full JavaScript parse for any implementation. The problem set was very well contained, so I just needed to write something that worked. I abused that to its fullest. So instead of pulling out a proper parser, building an AST, and traversing the tree, I did a simple line-by-line check. The original form of this used a regular expression to get the import file path, but I ended up scrapping it. I didn't like the Regex differences between JavaScript and C, and didn't want this to be a comparison of Regex processing engines.
This program can be found here. The most important part is that I used a while loop to do the processing.
while (filesToProcess.length > 0) {
let file = filesToProcess.pop();
// Do processing
}This took surprisingly little time to write, and even at the largest scale, it was a fairly quick program. The slowest execution time for 1500 files was ~273ms on Mac and ~363 on Linux.
Async Node example
Moving on, I implemented the callback-compatible version of the same program to see the difference with just using the event loop properly. The biggest change I had to make was around that while loop. Now, instead of blocking each file, I would block in batches as I found them.
async function main() {
while (filesToProcess.length > 0) {
let fileRequests = [];
for (let file of filesToProcess) {
fileRequests.push(processFile(file));
}
await Promise.all(fileRequests);
}
}This program can be found here.
The resulting difference in performance was notable. In all but the tiny dataset, the program ran nearly twice as fast. The slowest observed time was ~124ms on Mac and ~278ms on Linux.
Basic C example
This is where implementation speed started to slow down a bit. Since it had been so long since I had written C, it took me way too long to get back into it. Eventually, I produced a working program. Again, I used a similar loop as seen before.
while (FILES_TO_PROCESS[FILE_TO_PROCESS_INDEX] != NULL)
{
processFile(FILES_TO_PROCESS[FILE_TO_PROCESS_INDEX]);
FILE_TO_PROCESS_INDEX++;
}The program can be found here.
Unfortunately, due to inefficient array scanning used in this program, execution slows down at larger scales. This had performance as bad as ~350ms on Mac and ~363ms on Linux.
Eventing C example
This one required a bit of work. Originally, I just tried putting some threads on the problem without building a legible abstraction. The main execution was done on a single thread, but the way file memory was managed created terrible performance due to the inefficiencies of the threading and mutexes required. In the end, I scrapped that implemenation. Eventually, I got to a much more stable version version that had a dynamically sized thread pool and a proper event loop. Now, as I mentioned before, the file APIs provided are a bit awkward, so it's not a perfect event loop. In this case, the implementation looks more like a managed thread pool for reading files and an event loop that dispatches work to the pool. All of the processing work still resides directly in a single thread in a loop.
The main event loop ended up being similar to this.
void run(EventLoop* loop)
{
while (loop->completed == 0)
{
// grow pool to maximum if we are not at the maximum
if (threadPool->size < MAX_POOL_SIZE)
{
// Calculate idle time.
if (idleTime > GROW_THRESHOLD)
{
GrowPool(threadPool, 1);
}
}
// dispatch events
if (loop->lastDispatchedEvent < loop->nextEvent)
{
// Find and dispatch pending read file events to idle threads.
}
for (int i = 0; i < threadPool->size; i++)
{
// Determine if the thread has a valid result
if (isValid)
{
// Invoke file handler on a single main thread
loop->handler(loop, threadPool->readers[i]->buffer, threadPool->readers[i]->fileSize);
// Reset thread state
}
}
}
}In the end, this version produced the fastest overall results, with the slowest result being ~113ms on Mac and ~195ms on Linux. Similar to the other C example, since I didn't use an efficient array search algorithm, this could likely be faster.
Considering the results
With all the runs completed, it was time to look at the results and see how things turned out. First, the original hypothesis of NodeJS tells us that using async APIs instead of sync APIs should produce a meaningful difference.
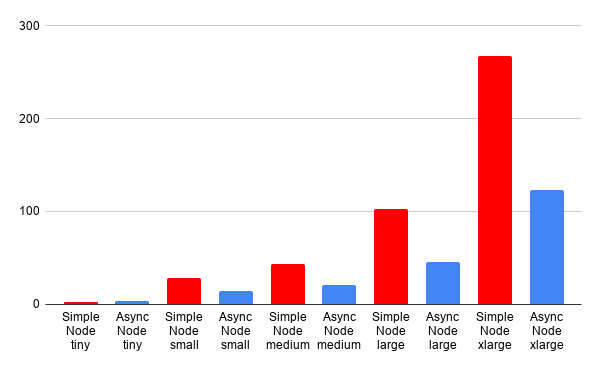
In this chart, we can see the difference between the sync node implementation (red) and the async node implementation (blue). At the smallest scale, the difference is negligible, but at larger scales, the difference is notable. The real benefit of the async pattern is distributing the wait time for file IO. This means the performance benefit scales with the number of files to be read, and we can see that clearly in this example.
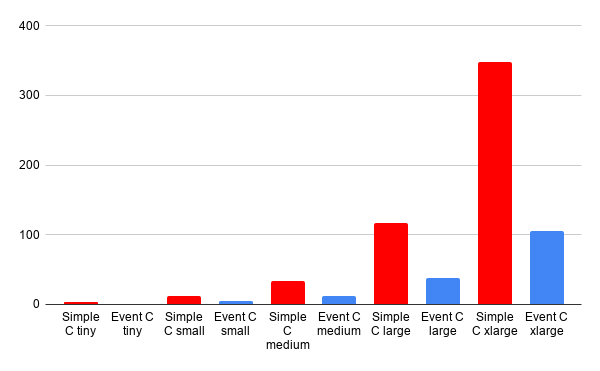
Now, if we compare the same in the C implementations, we see a similar pattern. Even though we are using a single thread for all the processing, we are still getting the same performance benefits we see in Node.
Conventional wisdom states that low-level languages are faster, so let's take a look at how the C implementation fairs against the Node implementation.
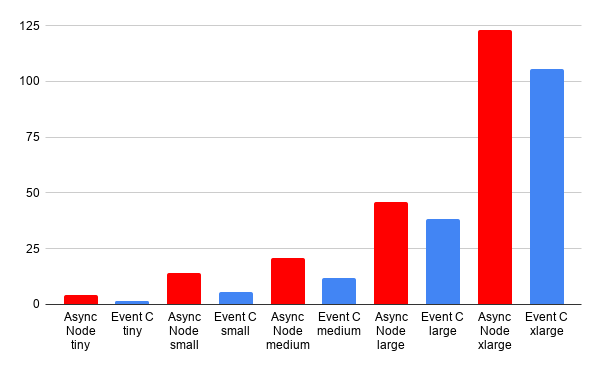
This shows that the C implementation is consistently faster. However, these differences are not nearly as significant as one might expect. If we consider this workload more deeply, a majority of the required time complexity comes from reading from the file system. This problem is not directly owned by either language. The time to load a file is largely dictated by the kernel and underlying hardware. Now, where things can get interesting and where some of the benefits lie is that C gives you direct control over memory. In the C implementation, I was able to get just a bit more performance by being clever with my memory allocations.
Lastly, let's consider the cost of getting things wrong. Remember how I mentioned the original C abstraction I created wasn't working well? If we compare this to the Node example, we can see that a poor implementation in C is quite detrimental.
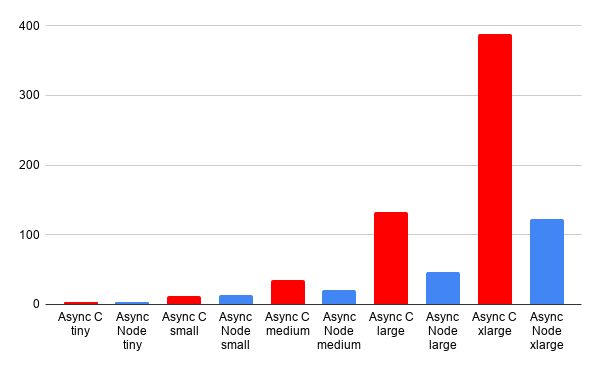
In this case, the results clearly show that the misuse of allocations and creation of additional thread contention on shared data will result in performance problems. Just because you have access to low-level primitives doesn't mean you are faster by default. If you are not careful, you have more ways to slow yourself down.
If you would like to look at the data and draw your own conclusions, you can find the raw data here.
What I learned from this experiment
In this project, I got to have a lot of fun learning about the lower level of event loops. I also got to see firsthand how building something in an event loop correctly can produce much better results. While writing C again was a bit of a learning curve, I was reminded just how much fun it is for me to think about low-level details like memory allocation and pointers. However, it was also a reminder that just because something is written in a low-level language doesn't mean it will be fast. It is all too easy to write a low-level program that runs way slower than a high-level language because you didn't think about the low-level primitives correctly. In the next blog, we will see that in action all over again.